Up next in 10

Machine Learning - Real Life Application : Credit Card Approval
https://www.tutorialspoint.com/market/index.asp
Get Extra 10% OFF on all courses, Ebooks, and prime packs, USE CODE: YOUTUBE10
Show More Show Less View Video Transcript
0:00
We are going to discuss one real-life application that is credit card approval
0:06
We have selected this very real-life application so that you can easily understand what is
0:10
the case study and how to implement it using our machine learning
0:15
So credit card company received thousands of applications for new credit cards and for each
0:21
and every application it contains information about the applicant like your age, marital
0:28
status, salary, outstanding debts and the credit rating, etc. So, problem here is that decide
0:36
whether credit card application should be approved and that is classify applications onto the two
0:43
different categories. One is the approved and the one is the not approved and rejected
0:49
So two classes are there. So in the outcome we are having two classes. One is approved and
0:53
the one is not approved. Data. a set of sample data records, example, the cases, case instances, training data set
1:04
about applicants, and described by key attributes or features, that is A1, a2, dot, AK
1:11
So, obviously, you should have a dataset. The data set will be gathered from the applications made by the applicants, and here this
1:19
particular data set will be having key attributes of features, that is A1,82, dot, AK
1:26
Classes. each sample is labeled with a predefined class and the available data set D is divided into two
1:34
disjoint subsets. So there is no overlapping their exclusive. So the training set that is a detrained for learning of the model and the test set that is
1:46
detest for testing the model also called the hand holdout set So one is the holdout set which will be used for the testing purpose and another one is the trend set which will be used for the testing purpose Another one is the train set which will be used for the training purpose and represented by
2:00
detrain. Goal, to learn a classification model that is from detrain that can be used to predict
2:09
the classes of detest or any future cases or instances. So now here we're having this
2:16
detrain on which the model will be trained and then. it will be asked to do the forecasting or prediction on the D test and from there we can
2:26
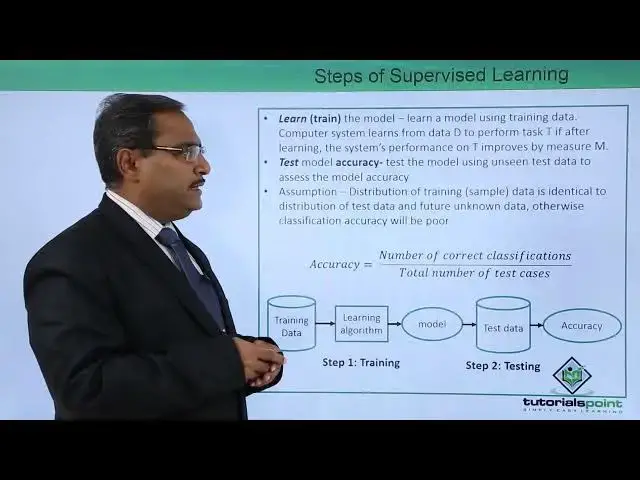
also evaluate the performance of the model. So learn there is a train, train the model
2:33
So learn a model using training data and computer system learns from data D to perform
2:41
tax T if after learning the system's performance on T improves by the measure M
2:48
So on this particular training set, the model will learn, the model will be able to learn
2:54
from the training set and now later the model will be used for the prediction
2:59
So test model accuracy, test the model using the unseen test data to assess the model accuracy
3:07
So assumptions, distribution of training, that is a sample data, is identical distribution
3:14
to the test data and future unknown data. Otherwise, the classification accuracy will be poor
3:22
That means the distribution of the training data set and the distribution of the tested
3:26
data set they are alike. So that's why we are going to, so we can select this particular tested data set very randomly
3:34
from the mother data set so that there should not be any biasness
3:38
If there is some biasness, then obviously the prediction accuracy will be too poor and
3:43
obviously the model will not be reliable and will not be usable So accuracy is equal to number of correct classifications by total number of test cases So depending upon the total number of test cases how many test cases have got correctly predicted
4:02
So the ratio that is the total number of correct classifications and total number of test cases
4:08
the ratio will give us the accuracy of the model. So training data, then learning algorithm
4:15
then the model will be formed so this is our step one also known as training
4:21
and then model will be formed and then test data step two that is a testing
4:26
then the accuracy can be measured so let us consider this particular sample
4:34
data set and it is containing ID age has job has own house credit rating and
4:42
class so here having multiple attributes are there and we are having multiple data sets are there
4:48
Now, from this particular data set we are supposed to form one classification model
4:55
So here is one model which has been suggested using our decision tree
5:00
So age young has job true or false in case of true we are having two by two in case of
5:09
false we're having three by three. What do they mean actually? So, age young and has job true
5:16
Just find it here. So age young, that means this part, and has job true, means this two cases only
5:26
So young age and has job true. So here you are finding this yes
5:32
So here I have been finding for the both cases we are finding yes. So how many times this combination has occurred two times and for the both cases I'm finding
5:40
yes So that why it is 2 by 2 In case of false that means has job falls age young and has job falls it is 3 by 3 Why 3 by 3 And here we are going for this no and 3 by 3
5:52
Why? Because you see, here we can do in this way. So age young, so this much, this much, and has job false, we are having three cases
6:02
And for the both cases, we're having no there. So that's why 3 by 3 has been written there
6:08
Similarly, let me go for the another one. So age middle and own house true, here we have written three by three
6:17
Why this three by three? So, let me go for the cross check. So own house is true and age middle
6:25
So age middle means we are having these five cases and own house is true we are having
6:30
here three cases and in both the cases we are having the yes, that is the class is yes, yes
6:35
the credit cut can be approved. So, as a result of that, we're having this three by three for years
6:41
So in this way, if you go for the cross check, you can make the video pause here, and
6:46
then also you can make the video pause here. You can go for the respective checking
6:51
Now what is the query which has been given to us? What is the respective new data set given to us for the prediction
7:00
So age young, has job false, own house is false, credit rating is good, then what is
7:07
the respective class. So, remember, age, young and has job is false. So, just remember
7:12
this one. So now here you find that age is equal to young and has job is equal to false
7:19
So the credit application, the credit card application should not be accepted, should be
7:25
rejected. So no is there. So in this way, we can do the prediction for that new test data
7:31
So, in this way, in this particular case, we have shown you one real-life application on
7:38
credit card approval. Thanks for watching this video
#Finance
#Credit & Lending
#Credit Cards
#Credit Reporting & Monitoring
#Computer Science
#Debt Management
#Machine Learning & Artificial Intelligence
#Machine Learning & Artificial Intelligence