live_tv
Livestream Starting Soon
00
Hours
:
00
Minutes
:
00
Seconds
Up next in 10

Job Scheduling in MapReduce
Show More Show Less View Video Transcript
0:00
In this video we are discussing job scheduling in MapReduce
0:05
When multiple clients will send their jobs for the processing, then how those jobs will
0:10
get processed in which order, in which scheduling, that will be decided by three different schedulers
0:17
The first scheduler name is FIFO, that is a first in, fast out, next one is the capacity
0:22
scheduler and the last one is the Fier scheduler. the job tracker and the resource manager, so they will be doing all these scheduling operations
0:32
This job tracker can deal with all the three schedulers, but the resource manager can deal
0:37
with only the capacity scheduler and the fair scheduler. So, let us go for more discussion on them to clear this concept with some proper diagrams
0:48
How does the job scheduling work? In Hadoop, different clients send their jobs to perform
0:55
the jobs are managed by the job tracker or the resource manager so here we are having two
1:01
scheduler one is the job tracker and the one is the resource manager and there are three different
1:07
scheduling schemes are available the first one is the first in fast out or fiffo scheduler next one is
1:12
the capacity scheduler and the last one is the fair scheduler this job tracker can can do all
1:19
kinds of scheduling schemes can implement but fifo is the default one but in case of resource manager
1:24
it can have only this capacity scheduler or the fair scheduler it can implement and the capacity scheduler is the default one the job tracker comes with three scheduling techniques and the
1:37
default is fiffo and the resource manager takes the capacity scheduler and the fair scheduler
1:43
and where the capacity scheduler is the default one now let us discuss one by one so first
1:51
one we are going for the fifo scheduler the jobs are queued in
1:55
the priority queue and send it to the job tracker. We know that only job tracker can implement
2:01
this FIFO scheduler scheme. So here we are having one priority queue. Multiple tasks, multiple
2:07
jobs are there sent from different clients. So the coloring is actually indicating that
2:12
multiple jobs are there from different clients. So now you see this is the first job where it has
2:17
been taken onto this particular slots. We are having multiple slots there on multiple nodes
2:23
this is our job tracker. So, what will happen? It will be doing the scheduling fast in
2:29
fast in, fast out. So, the jobs are queued in the priority queue and send it to the job tracker
2:34
When a job is scheduled, even its priority is lower, no preemption is allowed
2:40
So if any higher priority job comes later on, then the lower priority jobs might be in operation
2:46
but preemption is not allowed there. So now it will get executed
2:50
The lower priority job will get executed and making the higher priority job. priority job waiting and that is a main disadvantage of this FIFO scheduler scheme So so some higher priority process may wait for a long time So next one we are going for our capacity scheduler
3:07
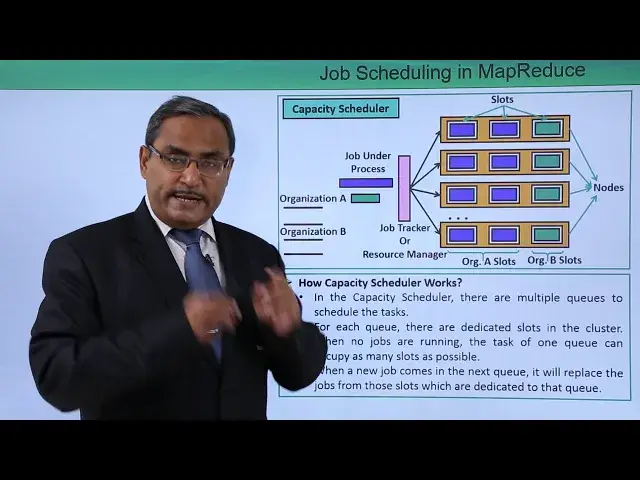
How capacity scheduler works. In the capacity scheduler, there are multiple cues to schedule tasks
3:16
You can find that it is our organization A, it is having one Q
3:21
This is our organization B, here we are having one Q here
3:25
this is our job tracker or the resource manager. So, let us suppose these are the respective job from organization A and this color is denoting
3:34
the job from organization B. And here we are having multiple notes as we had before also and multiple slots are there
3:41
Now in this case what will happen, all the slots will be dedicated for a certain organization
3:47
You can find that this is these are the slots dedicated for organization A and just consider
3:51
this color and it is for organization B. So, now in this way, the capacity scheduler will be working
3:59
For each queue, there are dedicated slots in the cluster, and when no jobs are running
4:05
the tasks of one queue can occupy as many slots as possible
4:10
Let us suppose that is no job has come from Organization B, but Organization A is having
4:15
multiple job spending, then they can take the other slots which were dedicated for
4:21
organization B also. when a new job comes in the next queue it will replace the jobs from those slots which are dedicated to that queue if the if any job comes later on for organization B then those slots which were the organization A job was working was accessing
4:41
so they will release them so that the organization B job can deal with this particular
4:48
dedicated slots. And that is known as the capacity scheduling. Next, we are going for the fair scheduler. So, how far
4:57
fair scheduler works. The fair scheduler is very similar to the capacity scheduler. When some
5:03
higher priority job comes in the same queue, it is processed in the parallel by replacing some
5:09
portion of the task from the dedicated slots. So here we are having this pool A and pool B. Here
5:15
we are having the multiple different tasks at their jobs under process. There is a job tracker or the
5:21
resource manager. There is a pool A slots. There is a pool B slots. Now what will happen is
5:27
If you can find that if there is this is the respective pool B slots, these are pool B task
5:33
so they will be allocated to the pool B slots. And these are the two tasks are there for pool A slots
5:40
Now, whenever the higher priority task will come, then some of the slots will be preempted
5:45
for this higher priority tax to get processed. And that's why the name has come
5:49
There is a fair scheduler. So in this particular video, we have explained with some proper diagrams to understand
5:56
their concept of job scheduling in MapReduce. Thanks for watching this video
#Computers & Electronics
#Programming