Up next in 10

Differences between Hadoop 1 x & 2 x
Watch more Videos at https://www.tutorialspoint.com/videotutorials/index.htm
Lecture By: Mr. Arnab Chakraborty, Tutorials Point India Private Limited
Show More Show Less View Video Transcript
0:00
difference between Hadoop 1.X and 2.X. So, let us discuss what are the different features
0:06
have got added with the new version of Hadoop, that is, Hadoop 2.X
0:11
Hadoop 1.X was having a basic features are there. So, we had the Hadoop, that is the HDFS, we had the map reduce, we're having the respective
0:20
hype, but in case of Hadoop 2.X, we have got so many different components and features
0:26
have got added. So, let us go for some more detailing about them
0:30
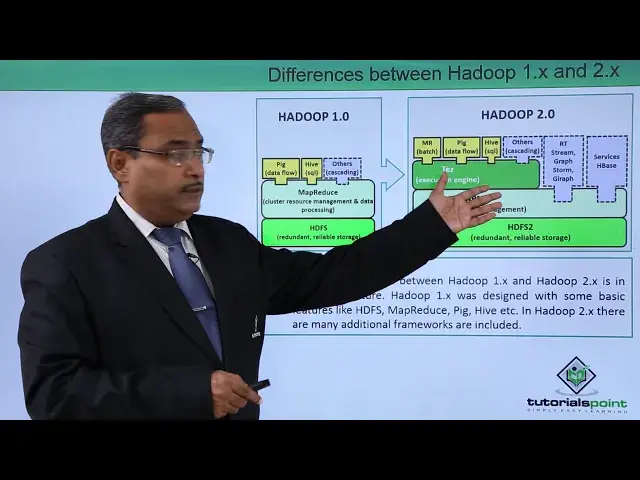
So, this is our Hadoop 1.0. We are having here the PIG, the HIB and the others are there
0:38
And here we are having this MAPReduce which is required for cluster resource management
0:42
and data processing. We are having the SDFS which is redundant reliable storage, that is Hadoop distributed file system
0:50
But if you consider this Hadoop 2.0, it is having so many different other components are there
0:56
We are having this MAP produce, we are having PIG, HIP, so they were having HIP, so they were
0:59
already there in the version 1.0. Now we are having the other features like your RT stream
1:06
We are having Graffstrom Zruff we having the services from H having this stage for this execution engine yearn that is yet another resource negotiator cluster resource management
1:21
SDFS2, the version has become HDFS2, redundant and further reliable storage. So the main difference between Hadoop 1.X and Hadoop 2.X is in their architecture and
1:33
Hadoop 1.X was designed with some basic features. like our HDFS, PIG, MapReduce, Hib, etc
1:42
So, these are the basic features we had in our Hadoop 1.X
1:46
And also Hadoop 1.X was having so many different drawbacks, and that's why Hadoop 2.X has come in the market
1:53
So, in case of Hadoop 2.X, there are many additional frameworks have got added
1:58
As we have discussed, here we're having this year on. SDFS2 is that second version I'm getting T.A. T.H
2:05
We're having the respective H-base. We are having the storm and so on
2:10
So, let us go for one comparison table for the better understanding what was not there
2:14
and what has come. So here we are having one comparison table for you So it supports only MapReduce tool in case of Haddub 1 It supports more than the basic map reduced tool like our Spark HBS etc Next one is that Hadoop 1 was having
2:34
maximum limit was 4,000 nodes per cluster. But here the limit has got too much increased
2:41
So it is scalable up to 10,000 nodes per cluster. So now it is capable to deal with huge amount
2:48
of data. It was the 4,000 number of nodes per cluster. Now it has become 10,000 number of
2:54
nodes per cluster. Works on slots, each slot can run either map or reduce task. So here
3:02
works on containers and the containers they can do generic tasks depending upon the business
3:08
logic needed. We can do the tax implementation accordingly. So single name note is used and multiple
3:16
NAMNodes may be used for the load sharing if we require, Hadoop 2.AX supports multiple
3:22
name nodes. So, supports only Linux system and it supports Microsoft Windows system also
3:29
So it supports only Linux and it supports also the Microsoft Windows system There is another some points are there No additional files are needed to execute a map reduce program but in case of Hadoop 2
3:44
X to run the program on Hadoop 1.X in 2.X we need some additional files there
3:51
So here if you write a program in Hadoop 1.X and if you want to run that program, that is
3:57
a running of the program of Hadoop 1.X in the 2.X environment we require some X
4:03
files so MapReduce does both the processing and the cluster resource management
4:09
but here we are having the yearn which will be doing the job for us so the cluster
4:14
resource management is done by yearn and processing is been done by another
4:18
processing models next one is that failure of name node affects the stack and
4:24
here hype pig edge base all are responsible for handling the name note failure so
4:31
So, when the name note will have the failure, in that case, this high pig and edge base
4:37
so they will take care of that situation and the system will be restored and revived
4:42
So these are the differences between Hadoop 1. X and 2.X. We have made one comparison table for your better understanding
4:49
Thanks for watching this video
#Programming
#Jobs & Education