Up next in 10

Machine Learning - Categorization of Machine Learning
https://www.tutorialspoint.com/market/index.asp
Get Extra 10% OFF on all courses, Ebooks, and prime packs, USE CODE: YOUTUBE10
Show More Show Less View Video Transcript
0:00
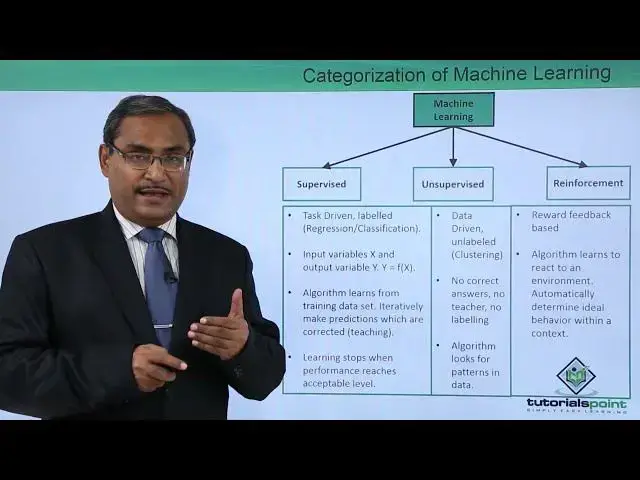
In this video we are going to discuss categorization of machine learning
0:07
Machine learning can be categorized mainly into three heads. The first one is the supervised, next one is the unsupervised, and the last one is the reinforcement
0:17
So we shall discuss one by one. Supervised learning. So supervised learning is tax-driven, labeled, and here we usually use the methods like
0:28
regression, classification, and input variables X, and if the output variable is Y, then
0:36
Y is equal to function of X. This algorithm learns from the training data set, iteratively
0:43
make predictions which are corrected and through the teaching, and learning stops when
0:50
the performance reaches to the certain acceptable level. So these are the features of supervised learning
0:57
So, it is tax driven. One tax will be given to that model after being trained and the tax is supposed to
1:05
get performed. That means the model will do some classification, that means some new data set will be given
1:12
to the model after being trained and then the model will do the classification of that given
1:18
data that is a task or some regression will be there with the help of which it can predict
1:25
some data. So, in case of continuous data, we are having this regression in case of discrete data
1:33
will be having this classification. So that is known as the tax driven
1:37
Now the question is coming, what is labeled? Why this particular data set will be called as labeled
1:45
So for this one, let us go for the next slide once
1:49
So this is our very famous Irish data set and this Irish data set we have used in our multiple
1:56
different examples in this tutorial in the implementation using Python and this particular
2:02
ID's data set here I put a part of that it is having a long data set there it is having
2:07
attributes like your sipple length sepal width pittal length and pittal width and that
2:15
is our species so this is the respective sipple length with pital length width are given
2:23
and these values are given and it is classifying it as three different types of pieces. So, that means this particular data set is having three
2:32
classes. So, one is the versicolor. This one is the setosa and the last one is the virginica
2:40
So, there are three different flowers are there and their respective four attributes are given
2:45
and the pieces has been concluded. So that is our outcome. That is our classes. So how many
2:52
classes this particular data set is having three classes? So as this outcome is also mentioned here, this outcome is mentioned
3:00
So that's why this data set will be known as the labeled data set
3:05
So that's why in the previous slide we had this one taxed event, we have discussed, and
3:10
that's why it is called labeled. So supervised learning is labeled because this very particular fact for certain attributes
3:17
the outcome is given to us. So our model will be trained with this data set and then a new data set will be given
3:25
That means the respective sepal length, sepal width, pittal length and pittal with will be given
3:30
and then our model which has been trained properly will be predicting the target flower type
3:38
That is one of the classes of this versicolor, cetosa and virginica
3:44
Let us see another example. I think that will clear about doubts
3:48
So here you see we are having muffins and cupcakes. And these muffins and cup cups we are having here
3:55
I have just put the pictures here for a better understanding. Here this is a long data set is given
4:01
What are they? They are nothing but describing the respective recipes for this muffin and cupcake
4:10
So these are the different ingredients which will be required. So flour, milk, sugar, butter, egg, baking powder, vanilla and salt
4:20
So different proportion. the respective proportions are given and then it is labeled that this particular recipe for
4:29
this cupcake this particular proportions are for this muffin so my model will get trained
4:35
and then I shall give a different proportions and then my model will tell using artificial
4:41
intelligence that this recipe is either for muffin or for cupcake so how many classes are you
4:48
having here two classes are there muffin and cupcake so in this
4:52
way this output this particular data set will be known as labeled so that means we are
4:59
having prior information and this information will be fed to the machine learning model
5:05
the model will be trained and then we shall give some some unseen input and then the
5:11
model will predict this is known as supervised learning so input variables x and output
5:18
variable y then y will be is equal to function of x
5:22
Algorithm learns from the training data set as I discussed earlier iteratively make predictions which are corrected that is the teaching So learning stops when the performance reaches to the acceptable level so now let us go for this unsupervised
5:39
learning now what is unsupervised learning it is data driven unlabelled here the method which will be using is mainly the clustering and no correct
5:51
answers no teacher no labeling algorithm looks for patterns in the data
5:57
So, here we have written the main key points of this unsupervised learning
6:02
So I think it would be better. Let us go for one example that why it is called data driven and unlabeled
6:10
Now see this particular data set for unsupervised learning. So what is happening here
6:17
You see here we're having multiple different items. Tea or coffee, sauces, confectionery, pudding, puddings and desserts, frozen, reserved blades
6:26
and so many, so many items are there. So, what are there? Actually, we are having multiple transactions, say, in a shopping mall
6:33
So, these items are there and in a particular shop rather, in these items are there
6:38
And we have considered different bills which have been made throughout, say, last 10 years
6:44
So, in the case, we are just putting 0 and 1 only to indicate that these items occurred in the same bill
6:52
And this another combination is there. only one item has been purchased frozen in another bill in this we are having
6:58
say crores of such data sets we are having crores of such records in this
7:03
data set now I shall have to find out the pattern that means which items are
7:09
occurring very commonly in one bill so here you see that is no outcome
7:15
there is not teaching there is not training there is no labelled it is data
7:21
driven so it is known as unsupervary learning. Try to get my point. Here you see that is nothing outcome. No classes are there
7:29
pre-given. So, what we are having? We are having a huge set of data. From where what we are
7:35
trying to find out? Say one particular pattern. What pattern? Which items are occurring very frequently
7:41
in the billing process? So, in the case, in the case, obviously, if we find that this item
7:47
and that item has been sold very frequently in the same bill, then you can go for some
7:53
what should I say, some offer may be given to that, some combo offer of those two items
7:59
and where to place those two items in which shelf, in which rack, where to place them
8:05
and how to place them. So, we can do the business planning and you can maintain, we can
8:10
mention the, we can implement some, some planning for that. Strategy can be also implemented
8:17
for that. So, this is known as data driven. So, data set for unsupervised learning
8:23
So, let me revise once again. This is known as unsupervised learning
8:28
That is data driven unleveled. Here we will be doing the clustering
8:33
Clustering means we are trying to find out the group of items which are having some similar
8:39
properties or which are which items are within a very small, some predefined distances within
8:47
the predefined distances. So in this way we can do the clustering
8:51
And then no correct answers, no teacher. no leveling. So this particular this particular data set will be given to our model. So
9:00
model will try to find out, we'll try to train itself and we'll try to find out some pattern
9:05
in our data. So algorithm looks for patterns in data. So that is our unsupervised learning
9:11
So let me go for the reinforcement. So that is a reward feedback based. Algorithm
9:19
learns to react on an environment automatically determine ideal behavior within a context
9:26
So, this is our reinforcement. Now, what is that actually? Let us suppose when we usually play a computer game, then most of the time, we are having
9:38
some idea. I have seen that some other person have played that game
9:42
I was with him or her. So I am having some idea. but when I'm playing with that game, so some initially I was failing to move to the next level
9:52
of the game. So what was happening? I was causing some mistakes
9:56
Some faults were there in my playing. Strategy was not good. So that's why I was missing to move to the next level
10:04
So from there I'm learning. And when I got, I got my chance to move to the next level, next level, next level, next level
10:12
each and every time I'm getting rewarded and I'm making. myself learning, I'm making myself learned that this is the way in which I should play
10:21
So, this is known as the reinforcement learning. Let us suppose when a particular kid is trying to learn how to drive a cycle, so how to do
10:32
the cycling, he or she might be having idea looking at some other people that we should
10:39
paddle, we should hold this respectively handles and so on. So, the mechanism must be known to them, but when they are learning, so they are getting
10:49
this idea, sometimes they're falling, having some painful experiences. So, from there, they're getting this idea that what has to be done, what has not to
10:58
be done sometimes the rewards are coming from the parents that you have done a good job Yes you are now a perfect rider So in those cases getting the rewards the kid is learning that how to do the cycling
11:11
So that is our reward-based reward feedback-based. Algorithm learns to react to an environment, automatically determine ideal behavior within a context
11:23
So in case of reinforcement learning, we're having two things. one is the agent and the one is the environment so agent will give some input to the
11:33
environment and environment will give some feedback to the agent and in this way the agent
11:38
will learn from the environment so this is of a machine learning so it can be categorized
11:44
into three heads supervised unsupervised and reinforcement now let us let us discuss
11:51
the machine learning coordinates so supervised learning in case of on the discrete
11:57
data will be going for classification of categorization and in case of continuous data
12:03
will be going for regression. So, in case of Irish data set whatever we discussed, then you can go for the classification
12:10
or categorization. The petrol length and simple length and width will be given to us and then a new data site
12:18
will be given to us on which we shall go for the predictions
12:21
So we can go for the classifications and here in case of predicting something where, where
12:27
we are having y is equal to function of x. So, for a new x I can calculate this value of y
12:33
So, regression can be applied in case of continuous data. In case of unsupervised learning, in case of discrete, we'll be going for clustering
12:42
Clustering I told you this one, we are trying to find out similar data in a certain
12:45
group or cluster having got either similar properties or having the distance within a certain limit
12:53
Another one is that dimensionality reduction. So question is coming in. is coming in the mind that what is the dimensionality reduction. So in statistics, machine learning
13:03
and the information theory, dimensionality reduction or dimensional dimension reduction is a process
13:11
of reducing the number of random variables under the consideration by obtaining a set of principal
13:18
variables and it can be divided into feature selection and feature extraction
13:24
So, this is our dimensionality deduction. Now, the question is coming in the mind that what is our principal variables and what
13:35
is our feature selection and feature extraction. So feature selection and feature extraction means that we know that feature selection means
13:45
we are having multiple attributes in a data set. We shall try to find out those features which is actually related with the outcome
13:53
So, we can select some of the features because if you go on dealing with huge number of features
13:59
and attributes in the data set, then obviously the computational complexity will be too high
14:06
So in that case, you can go for the feature selection and in case of feature extraction
14:10
will be going for secondary layer of some extraction from the data set
14:15
That means we are not going for the classification, but we are trying to find out some
14:19
extra information from our data set. So, let us, we shall discuss them in the later slides
14:24
So, we'll be having the clear conception. So that is known as the dimensionality reduction
14:32
So at first we're discussing with this classification and class study. So classification is the problem of identifying to which of a set of categories, also known
14:42
as classes, a new observation belongs on the basis of a training set of data containing
14:48
observations or instances whose category membership. is known to us. So, that is just considered our Irish data set, just consider our muffin
14:59
and cupcake data set. In those cases, we know the previous information because the
15:05
data set was labeled. So, now we shall try to predict on a new data, new data set given
15:10
to that. So classification is considered an instance of supervised learning and learning
15:17
where a training set of correctly identified observations are available. The corresponding unsupervised procedure is known as clustering and involves grouping data into
15:31
categories based on a measure of similarity or some distance. So we have discussed this one, that is a classification and clustering
15:42
So example, this is an example of classification problem where there are two classes
15:47
one is a low risk and another one is a high risk customers so the information about a customer
15:53
makes up the input to the classifier whose task is to assign the input to one of the two classes
16:00
after training with the past data a classification rule learned may be of the form like this
16:08
just consider this one if income is greater than theta one and savings is greater than theta two
16:15
then low risk else high risk so here we have plotted income along the x-axis
16:20
here we have plotted the savings along y axis now what is income what is the
16:24
problem actually let us suppose a credit cut company has got multiple
16:28
crores of different applications have been made by the applicants so all those application data is available now the credit cut company will decide whether they will issue a credit card for the respective applicant or not whether it is going for two classes
16:45
Low risk, credit card should be given and high risk credit card should not be allowed
16:51
So now you see when the income value is greater than theta 1 and the savings is greater
16:57
than theta 2, just look at here. So theta 1, more than theta 1, and
17:02
greater than theta 2, then that is our low risk zone. We have marked this one with some other color
17:08
Otherwise it is our high risk zone. So that is the respective clustering we have done here
17:16
So now let us go for the next one. So in this way the classification and the clustering, here we have done the classification
17:24
and whenever we are trying to find out some group of data in that case, having the similar
17:30
properties or some within a distance then we can go for the class studying in that
17:35
case. So, here we are having two classes. One is the low risk and one is the high
17:39
risk. Next one we are going for the regression. So a regression problem is when the output
17:47
variable is a real value such as dollars or say weight instead of a class. That means it is
17:54
a numeric. Estimate the relationship between a dependent variable and one or more independent
18:00
variables also known as predictors so here you can say that we are having the
18:04
sales figure for a television model can depend on several factors so that is
18:10
the screen size display type brand resolution technology etc so that will
18:15
decide the cells of that particular for the particular instrument so now this
18:20
television is having multiple different properties so this instrument we are trying to find out that what is the respective sales prediction so here
18:30
we consider just one attribute that is a screen size of the television and plot the
18:35
corresponding prices. So, here we have plotted the screen size and here we have plotted
18:40
the respective sales figure. And here we are having the screen size we have plotted and
18:46
plot the corresponding prices, that is x is equal to screen size and y is equal to sales figure
18:52
So we try to find the deletion function that best matches these two values
18:58
So here we have plotted the screen size. Here we have plotted the prices means actually you are trying to mean that one as the sales figures
19:05
So now here we are having multiple dots and we are suggesting one line that is known as
19:09
the regression line and this is the respective equation for the regression line
19:14
So for some unknown X I can find the respective Y value
19:18
So Y is equal to f of x. Next one we are going to discuss that is the dimensionality reduction
19:26
So dimensionality reduction is the process of reducing the number of random variables under consideration by obtaining a set of principal variables
19:36
So, it can be divided into feature selection and feature extraction. So, that is known as the dimensionality reduction
19:44
A data set may have hundreds of attributes, thousands of attributes. If I go on doing calculations and learning process with all those attributes, then obviously
19:55
the computational complexity will be unnecessary high. So, in those cases, we should select those attributes which are the prime attributes, also known
20:04
as the principal attributes, on which will be training our model and later we shall expect
20:10
a good prediction out of them. So this is known as the dimensionality reduction
20:15
So next we are going for the feature selection. Feature selection approaches try to find a subset of the original variables, also called the features
20:23
or attributes. It is about choosing some of the features based on some statistics
20:29
score so we might be having multiple different features so we can make those
20:34
features with some weightage values so that those features with the weightage
20:38
value smaller that means that feature is having lesser importance and those
20:43
features which are having the the weightage value higher that means that
20:47
feature is having the higher importance so in this way we can go for this
20:53
feature selection next one is the feature extraction so feature extraction transforms the data in the high dimensional space to a space of fewer dimensions, it is using
21:05
techniques, it is using techniques to extract some second layer information from the data
21:12
So, as example, you just see this one, interesting frequencies of a signal using Fourier transform
21:18
So, if we find this particular one, so you are going for a second layer of, that is a second
21:24
layer of information you are trying to find out. and that is known as feature extraction
21:29
So the data set is actually meant for something but we are trying to find out something new from that one, from that particular data set we are trying to predict something new or
21:37
calculate something new and that is known as feature extraction. Dimensionality reduction helps in data completion, reduces computational time and removes
21:47
the redundant features. So in this way we have discussed all these respective categories and different
21:56
classifications, clustering, categorization, dimensionality deductions, everything we have discussed into details. Please watch all the videos in the tutorial for your better understanding
22:08
Thanks for watching this video
#Cooking & Recipes
#Desserts
#Food
#Computer Science
#Culinary Training
#Machine Learning & Artificial Intelligence
#Machine Learning & Artificial Intelligence